Virtualisation matérielle et Container

Dans mon précédent billet sur le Cloud Computing, j’ai abordé des éléments tels que la virtualisation et les containers. Il s’agit de concepts relativement proches mais qui font parfois l’objet de houleux débats entre ce qui est de la virtualisation et ce qui n’en est pas. Ce billet vous proposera une explication de ce qu’est la virtualisation matérielle, et en quoi elle est intéressante associée à la containérisation.
La virtualisation matérielle
La virtualisation matérielle est le fait de diviser de manière logique des ressources informatique physique. L’idée remonte à la nuit des temps de l’IT puisqu’elle a été mise en oeuvre dans les années 1960 pour allouer de manière logique les ressources mainframes entre les différentes applications. L’expression “virtualisation” s’est depuis élargie, mais le concept de base reste le même.
L’idée était de créer des machines virtuelles, ou “pseudo machines”, qui se considéraient elles-même comme de vrais ordinateurs physiques, mais se partageant en réalité les ressources d’une même machine. Cette machine d’accueil est appelé “hôte”, ou “host” en anglais. La machine virtuelle est quant à elle appelée “système invité”, ou “guest”. L’hôte hébergeant des machines virtuelles utilise un logiciel appelé Hyperviseur qui se charge de créer le lien entre les ressources physiques de l’hôte et les machines virtuelles qu’il va héberger.
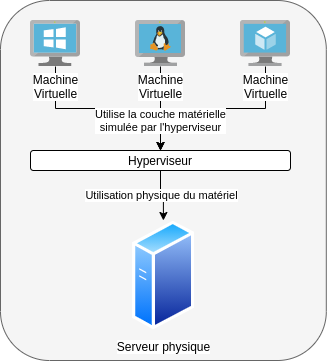
En plus d’une exécution d’un logiciel potentiellement différent de l’hôte, l’invité est également capable d’utiliser des interfaces physiques de ce dernier, comme les cartes réseau, le clavier, la souris, ou le disque. Ces accès ne sont généralement pas directs, l’hôte est capable de restreindre les possibilités des invités en fournissant des interfaces simulées. Par exemple dans le cas des interfaces réseau, l’invité peut obtenir un pont avec la carte réseau physique de l’hôte, tout comme il peut être placé derrière un sous réseau utilisant une carte virtuelle gérée par le système hébergeur. Les capacités d’accès aux ressources de l’hôte dépendent évidemment de comment le système est configuré.
L’intérêt de la virtualisation
Le premier intérêt de la virtualisation est financier. En effet, avant que celle-ci ne se répande en entreprise, les applications étaient souvent hébergées sur des machines physiques dont les ressources n’étaient sollicités qu’en cas d’utilisation des dites applications. De ce fait, les serveurs avaient une puissance dormante largement sous exploitée. La virtualisation permet ainsi de mutualiser les ressources de ces machines pour les exploiter de manière plus efficiente.
La virtualisation apporte un certain niveau de résilience pour les systèmes invités. Ceux-ci n’étant au final que des données sur un espace de stockage, ils peuvent être répliqués et clonés à volonté. Ainsi, si l’hôte connaît une défaillance ou est détruit, les invités peuvent être redémarrés depuis un autre système. Les hyperviseurs disposent généralement de mécanismes de haute disponibilité permettant de basculer d’un hôte à l’autre les invités en cas de perte d’un membre de la ferme.
Ces mécanismes de réplication sont également très pratiques pour des gestes de maintenance et d’exploitation. Les hyperviseurs sont souvent capables de déplacer une machine virtuelle en pleine exécution d’un hôte à l’autre. Ces fonctionnalités permettent ainsi de migrer les invités sur d’autres systèmes sans interrompre la continuité de service (mais avec une petite dégradation de performances parfois). Les systèmes hôtes ont également assez d’intelligence pour gérer leurs ressources de manière efficiente et ainsi bouger automatiquement des invités qui auraient besoin de trop de ressources vers une plateforme moins sollicitée par exemple.
Parmi les autres cas d’usages de la virtualisation, nous pouvons aussi citer l’isolation des invités avec des mécanismes de bac à sable (sandbox) au niveau logiciel et réseau permettant de tester des choses sans altérer l’hôte. La flexibilité des environnements qui peuvent être rapidement créés grâce à des modèles à déployer et à détruire une fois l’utilisation terminée pour un coût réduit. Ou encore faire tourner un logiciel qui ne serait pas compatible avec le système hôte.
La containérisation
La containérisation est un niveau au dessus de la virtualisation matérielle. On l’appelle également “virtualisation au niveau OS” ("OS-Level virtualization"). Contrairement à la virtualisation matérielle qui permet de partager des ressources physiques, la containérisation se place au niveau logiciel.
Le concept des containers
Les containers sont une isolation au niveau logiciel, dans le système d’exploitation. Dans ce concept, les processus sont isolés par le noyau de l’OS qui permet ainsi leur existence dans un espace utilisateur dédié. Ici, l’hôte ne présente pas une imitation de composants physiques sur laquelle un invité vient s’installer, mais un environnement d’exécution pour un applicatif.
Dans la mesure où la containérisation est gérée par le noyau du système d’exploitation, elle ne permet pas d’émuler un système différent de l’hôte. En effet, contrairement à la virtualisation matérielle qui permet, par exemple, à un ordinateur Windows d’avoir une machine virtuelle Ubuntu, un container est lié au système qui l’exécute. Ainsi, l’image du container partage le noyau du système d’exploitation hôte. Cela permet donc aux images Linux de fonctionner sur la majorité des distributions puisque le kernel reste le même. Par exemple, on retrouve de nombreuses images Docker qui sont basées sur Ubuntu, Debian ou encore Alpine. Toutes ces images peuvent tourner sur une hôte utilisant Red Hat.
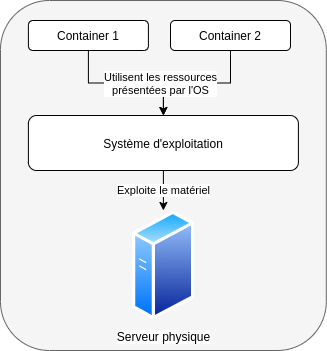 Les containers peuvent être bien entendu hébergés sur des machines physiques, mais l’intérêt est faible.
Les containers peuvent être bien entendu hébergés sur des machines physiques, mais l’intérêt est faible.
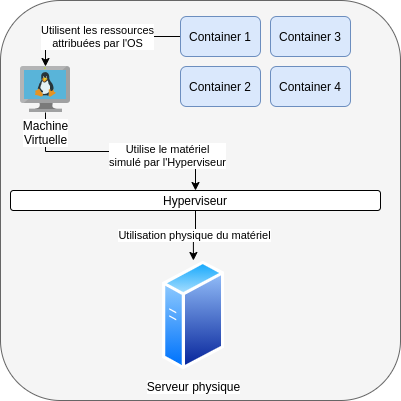 Les containers sont plus généralement hébergés sur des machines virtuelle pour partager les ressources du serveur physiques.
Les containers sont plus généralement hébergés sur des machines virtuelle pour partager les ressources du serveur physiques.
Le principe des containers ne date pas d’hier non plus, même s’il a été fortement popularisé avec Docker à partir de 2013. Les méthodes d’isolation de process existaient déjà avant avec par exemple le chroot des systèmes Unix datant de 1979. Le principe était de faire croire à un process applicatif que l’emplacement des fichiers système était à un endroit différent des véritables. Cette méthode permettait ainsi d’emprisonner le process dans un espace délimité qui rendait impossible toute action en dehors. Attention, le chroot n’est pas un mécanisme de sécurité pour autant car il peut être outrepassé par des process ayant des droits d’accès trop élevés.
La containérisation telle qu’on la connaît aujourd’hui est arrivée avec le système LXC (LinuX Containers) intégré au Kernel Linux à partir de 2008 qui permet une véritable isolation de ressources logicielles, réseau, identifiant utilisateurs, et système de fichiers.
Le fonctionnement des containers fera l’objet d’un article à part entière, donc j’éviterai d’alourdir celui-ci en restant sur l’idée générale.
L’intérêt des containers
L’intérêt premier d’un container est qu’il s’agit d’une image contenant un environnement d’exécution applicatif complet prêt à l’emploi. Cela signifie qu’en l’exécutant, on aura tout le nécessaire pour garantir le bon fonctionnement de l’application sans avoir à altérer le système hôte en installant d’éventuelles dépendances. C’est un cas d’usage relativement similaire à celui répondu par les méthodes de distributions applicatives comme Snapd, AppImage, et autres, mais leur portée est plus grande qu’une simple application portable.
Exemple : un développeur veut tester son application avec différentes versions du runtime. Plutôt que d’installer n versions sur sa machine et risquer une instabilité de son environnement de travail, il peut utiliser une image de container de ceux-ci et les exécuter à la demande. Une fois terminé, le container pourra même s’autodétruire.
Autre cas d’usage qui, pour le coup, m’a été nécessaire : j’ai du recourir à des images Docker pour compenser les versions plus vieilles de certaines bibliothèques sur CentOS 7 qui n’étaient plus compatibles avec certains outils.
Un second intérêt est la reproductibilité d’une exécution d’un container. En effet, l’image étant elle-même immuable, lorsqu’un container démarre il repart systématiquement de son état d’origine. Vous allez me dire : mais comment cela se passe si on doit sauvegarder des données (ex : une base de données dans un container) ? C’est dans ce genre de cas qu’entre en jeu la mécanique des volumes. Les volumes sont une fonctionnalité de services de containérisation qui permettent de monter un disque de l’hôte pour y écrire les données de l’application. Ainsi, à son prochain démarrage, elle pourra s’appuyer dessus.
La reproductibilité est donc le fait d’avoir systématiquement le même comportement lors de l’exécution du container. L’intérêt y est tout sauf négligeable : l’application que le container fait vivre sera toujours stable et ne sera pas parasitée par un éventuel effet de bord causé par l’installation d’une bibliothèque tierce ou autre mise à jour cassante.
Enfin, l’autre grand intérêt des containers est l’orchestration avec laquelle ils peuvent être organisés. Des outils de plus haut niveau qu’on appelle orchestrateurs permettent de gérer les instances de containers pour notamment faire apparaître de nouvelles si l’application atteint une charge critique et qu’il faut la répartir, ou encore redémarrer une instance en cours de mise à jour tout en gardant le service ouvert avec d’autres actives. Nous développerons ces aspects dans l’article qui sera dédié à la containérisation. Si je devais faire un petit name drop pour le plaisir, vous verriez tomber un certain Kubernetes.
La virtualisation et la containérisation travaillent ensemble
Cela s’est fait graduellement au fil des années, mais depuis quelques temps on ne passe plus à côté de ces méthodes de déploiement applicatifs. Avec la virtualisation matérielle, le serveur est désormais un logiciel qui se partage les ressources d’une machine physique avec un autre. Cependant, une machine virtuelle reste potentiellement exploitée de manière inefficiente si son seul travail est de servir un simple bout de logiciel (exemple : une VM faisant office de serveur d’application Tomcat dédié à une webapp).
C’est à ce moment-là que la containérisation entre dans la danse. En effet, plutôt que d’avoir une VM remplissant un ou deux usages, elle va devenir hôte de containers et ainsi remplir de nombreux petits besoins.
Un aspect architectural qui s’est beaucoup développé durant ces dernières décennies sont les microservices. Cette approche dérivée de l’Architecture Orientée Service (SOA) est très inspirée de la philosophie Unix qui nous dit de “faire seulement une chose, mais de la faire bien”. Ramenée au monde applicatif, cela signifie qu’au lieu d’avoir un logiciel monolithique qui fait plein de choses et alloue beaucoup de ressources, l’application est éclatée en une multitude de petits services qui remplissent une tâche précise. Au final, cette application n’est plus qu’une orchestration de multiples services qui sont appelés lorsqu’ils ont besoin de l’être et s’endorment pour laisser la ressource disponible quand inutilisés.
L’architecture micro services tire partie de la containérisation car chaque micro brique est un container disposant de son runtime et dépendances lui garantissant une exécution systématiquement identique, appelée à la demande et détruite quand elle n’est plus nécessaire. Ce modèle n’est cependant pas exempt de défauts, la latence (réseau, interprétation des messages, etc) et la complexité à architecturer une application en micro services font partie des principaux remontés.
Mis bout à bout, le travail conjoint d’une virtualisation matérielle et des containers signifie donc qu’un serveur physique pourra héberger X machines virtuelles, et que ces machines virtuelles pourront héberger X containers. Le X étant variable selon la puissance des environnements. On arrive donc à une utilisation optimale des ressources physiques (pour peu que l’applicatif soit bien écrit évidemment) qui tend à utiliser au mieux toute la puissance des serveurs.
Dans une infrastructure d’entreprise, nous obtiendrions une idée qui se schématise de la manière suivante, où chaque container propose un service applicatif de l’entreprise :
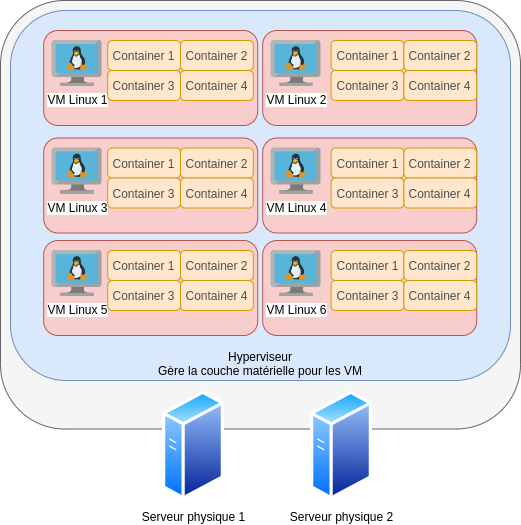
Comme vous pouvez le constater, une machine physique peut désormais répondre à beaucoup plus d’usages que ce qui était fait auparavant. La virtualisation matérielle a permis de mutualiser les ressources d’un serveur physique, et les containers sont venus en rajouter une couche pour optimiser l’utilisation des ressources d’un système d’exploitation.
Quelques ombres au tableau
Malgré tous ses avantages, le modèle des containers ou de la virtualisation a quelques petits soucis, notamment de sécurité.
Un risque partagé entre les VM et les containers sont les versions logicielles. Celles-ci peuvent être obsolètes et dangereuses à utiliser car comprenant des failles potentiellement exploitées et colmatées dans des versions supérieures. Une VM se doit donc d’être maintenue comme n’importe quel autre système d’exploitation car malgré l’isolation, c’est un composant qui peut devenir un vecteur d’attaque ou de fuite de données. Les containers ont le même risque car les images utilisées peuvent ne pas avoir été mises à jour et l’application tournera sur une version trouée de son socle technique (exemple : une vieille image Nginx contenant des failles).
Ces soucis sont souvent engendrés par une méconnaissance des capacités de ces outils. On peut créer et supprimer des VM comme on veut, tout comme un container peut être reconstruit à la volée et mis à jour. Cela implique néanmoins une adaptation du point de vue applicatif pour qu’il puisse supporter un modèle de déploiement de ce type.
Dans la même catégorie de l’obsolescence logicielle se trouve évidemment le fait que la virtualisation, c’est des composants techniques supplémentaires ajoutés à la chaîne de valeur. De ce fait, il est nécessaire de maintenir ceux-ci le plus à jour possible pour éviter l’exploitation de failles qui profiteraient d’une possible porosité entre l’hôte et l’invité. De même pour les containers, ils reposent sur des API du kernel qui peuvent être mises à jour avec celui-ci, ou bien un daemon pilotant l’interface entre le container et le kernel.
Un autre souci qui touche principalement les containers est leur mauvaise gestion par les développeurs ne maîtrisant pas la mécanique. Je l’expliquerai dans l’article qui leur est dédié, mais une image c’est un empilement d’états immuables qui sont amendés au fil de l’évolution de celle-ci. Plus on fait d’action dans l’image, plus les couches s’empilent et l’espace disque nécessaire augmente. Une bonne pratique est donc d’éviter de charger la mule et de passer par des images de build qui ne seront pas intégrées au produit final.
Conclusion
La virtualisation et les containers sont monnaie courante de l’informatique moderne. Ces technologies continuent d’évoluer et ne cessent de remplir des cas d’usages de plus en plus variés ou complexes. J’espère que cet article vous aura éclairé sur les concepts autour de ces deux domaines.
