What is GitOps ?

In my experience with the software delivery chain, we talk a lot about how the software is produced and delivered, but when it comes to make it live, the topic is less studied. Maybe that’s because the deployment is situated in the “Ops” domain of the DevOps timeline while the software production is on the “Dev” side. And we usually like to focus on Dev and less on Ops I suppose. Since I’ve mainly worked in the deployment part, I think it’s a very interesting topic because it’s one of the best examples to demonstrate how well the DevOps culture is implemented in a team or not. And one of the best examples in my opinion is the GitOps practice.
What is GitOps
According to the Linux Foundation OpenGitOps set, GitOps is based on four principles :
- Using a declarative description on the desired state of the system
- The desired state is versioned and immutable
- The desired state is pulled automatically and applied
- The system’s state is continuously reconciled and will attempt to maintain the desired state
In other words, GitOps is a pattern that considers a source code repository, in this case Git because of its popularity, is the truth of the desired deployment state. GitOps uses the benefits of the source code management to create immutable deployment configurations that will be applied to the target system. When a new state is committed on the repository, a synchronization agent (a tool dedicated to this purpose) will retrieve the new desired state on the source code repository and apply it to the system. Also, if any drift or divergence is detected, the agent will take correctives actions to bring the system back to the desired state.
Illustration of a GitOps usual workflow.

(Click on image for larger version)
On this diagram I’ve named the character ‘Ops’, but the Dev can also do the action. The desired state is a set of configuration files managed on a Git repository. When the configuration is updated, the GitOps agent (usually on the hosting platform, but it could be a third-party system) detects this change and will compare to the current desired and applied state. It establishes the reconciliation to perform and executes the action.
When we talk about GitOps, we usually think about cloud-native applications such as Kubernetes deployments, and that’s indeed one of the main use-case. However, GitOps can also be used for infrastructure management based on Infrastructure as Code - IaC - principle, and also configuration management deployed by softwares such as Ansible. If the implementation differs a bit, the purpose remains the same.
GitOps pros and cons for Ops
GitOps is a nice pattern to maintain a system and an infrastructure, but it also has some weakness that a team should be aware of in order to setup a proper organization.
| Pros | Cons |
|---|---|
| With Infrastructure as Code, the infrastructure elements of a system are defined as declarative files that can be easily managed, version controlled, and reproduced | Since Git is mainly a Develope’s tool, Ops teams may require some training to learn the Git concepts such as branches, commits, pull requests, code review, etc. |
| Deployments are consistent and standard. The deployment procedure will be the same whatever the target system since it’s based on declarative configurations. | GitOps requires some tools to work, especially the Sync agent. These tools should be also maintained and properly configured. Good news about them : they’re usually GitOps-managed themselves. |
| Since Git retains the history of a file, the deployment can be audited and verified. Also, with some policies on the hosting platform, the compliance of the deployment can be confirmed or blocked. | The initial setup and configuration of a GitOps environment can take some time if the team starts from nothing. Developing the IaC templates and the deployment manifest can require some time investment. |
| The documentation of the deployment process can also be managed on Git, meaning each version can have its own documentation version too and keep a consistent record of changes. | High Git dependency. Obviously, since it’s the source of the deployment, the Git hosting system must have a good availability rate. |
| Since the infrastructure and the application deployment are all configuration files on a Git repository, the disaster recovery process is greatly simplified because the infra and the application can be redeployed from the templates (of course, it doesn’t take in account the possible backup restoration which are aside the GitOps perimeter). | An improvised GitOps environment can become complex to maintain. The branching strategy, environment separation and conventions must be established at the beginning and understood by everyone. |
Also on the developer’s side, I would add a warning : the application must be properly designed for a GitOps pattern. Monolithic software are far more complex to maintain compared to microservices architecture. GitOps is better for the second case. It’s possible to maintain a monolithic system with GitOps (I did it), but it’s complicated (very).
Regarding the learning curve : nothing’s impossible, even if your Ops team has never touched Git. I’ve been in organizations that were not DevOps-friendly, with developers on a remote service center meanwhile the Ops team was maintaining and deploying the new softwares and they were never talking to each other.
Ne-ver, only through project managers (yep, this kind of cursed organization).
Thanks to a lot of automation and some investments on the good people (try to identify some key users that are curious or enthusiast with these patterns, they’ll be your Trojan horse for the rest of the team 😉 - because an organization change will be easier to adopt if it comes from the inside), I could lead some training and we were able to gain a lot of time and reliability for new versions deployment. Before that, deploying a new version was “All hands on deck !”, today it’s just a normal Tuesday. And I’m talking about a monolithic system, not a cloud-native application. You know, the good old fat-ass house of card system for which you touch something and it break.
Some GitOps implementation examples
Let’s show here some examples. As we said at the beginning, GitOps is better for Cloud-native apps such as Kubernetes deployments, but we can also use this method for more traditional softwares hosted on virtual machines. Since I don’t want this article to be too long, I’ll focus on the Cloud native app. Maybe I’ll write something for IaaS platforms later.
First : where should I put the deployment configuration ?
That’s usually a good question since the deployment configuration is stored on Git, it could be included in the application’s source code repository. Or not…
Actually, there is no strict and well established rule about where you should store your GitOps manifests. That really depends on various factors such as the organization of the teams and the application’s life cycle.
If the team responsible for the application’s development and deployment is the same, a mono repository approach (everything in the same repo : source code, IaC templates, deployment manifest, documentation…) could be envisaged. However, if there are several teams taking part of the system’s maintenance (such as a dedicated Infrastructure team providing the platform, developers delivering the application, ops deploying it…), the deployment manifest should be separated from the application’s code and the IaC templates because they’re not maintained by the same people.
To answer this question, you need to ask some to yourself such as :
- Who’s maintaining the code ?
- Should the code maintainer have write access to the deployment manifest ?
- Should the deployment maintainer have write access to the source code ?
- Who’s in responsible for each part ? Who’s allowed to perform which action ?
As you may see, it’s completely related to your organization’s Responsibility assignment matrix (the good old RACI).
Let’s try
Let’s host on a Kubernetes cluster the DevOps Solutions Map I’ve made. Since it’s a very simple application, the manifest can be like this :
apiVersion: apps/v1
kind: Deployment
metadata:
name: devops-map
namespace: devops-map
labels:
app: devops-map
spec:
replicas: 3
selector:
matchLabels:
app: devops-map
template:
metadata:
labels:
app: devops-map
spec:
containers:
- name: devops-map
image: ghcr.io/wivik/devops-solutions-map:v0.5.0
ports:
- containerPort: 5000
This manifest says : deploy three instances of the application using version v0.5.0, listen on port 5000. Let’s check on the cluster what is says :
$ kubectl get pods -n devops-map
NAME READY STATUS RESTARTS AGE
devops-map-5dfd68655c-9z26w 1/1 Running 0 29s
devops-map-5dfd68655c-ktxs7 1/1 Running 0 29s
devops-map-5dfd68655c-zrf7s 1/1 Running 0 29s
## Check which image is running
$ kubectl describe pod devops-map-5dfd68655c-9z26w -n devops-map
Name: devops-map-5dfd68655c-9z26w
Namespace: devops-map
(...)
Containers:
devops-map:
Container ID: docker://c3729af4961247f5edf078090bcf54d03acdfbb3f2496577dc8b55e8f94e756a
Image: ghcr.io/wivik/devops-solutions-map:v0.5.0
Let’s check my GitOps agent GUI :
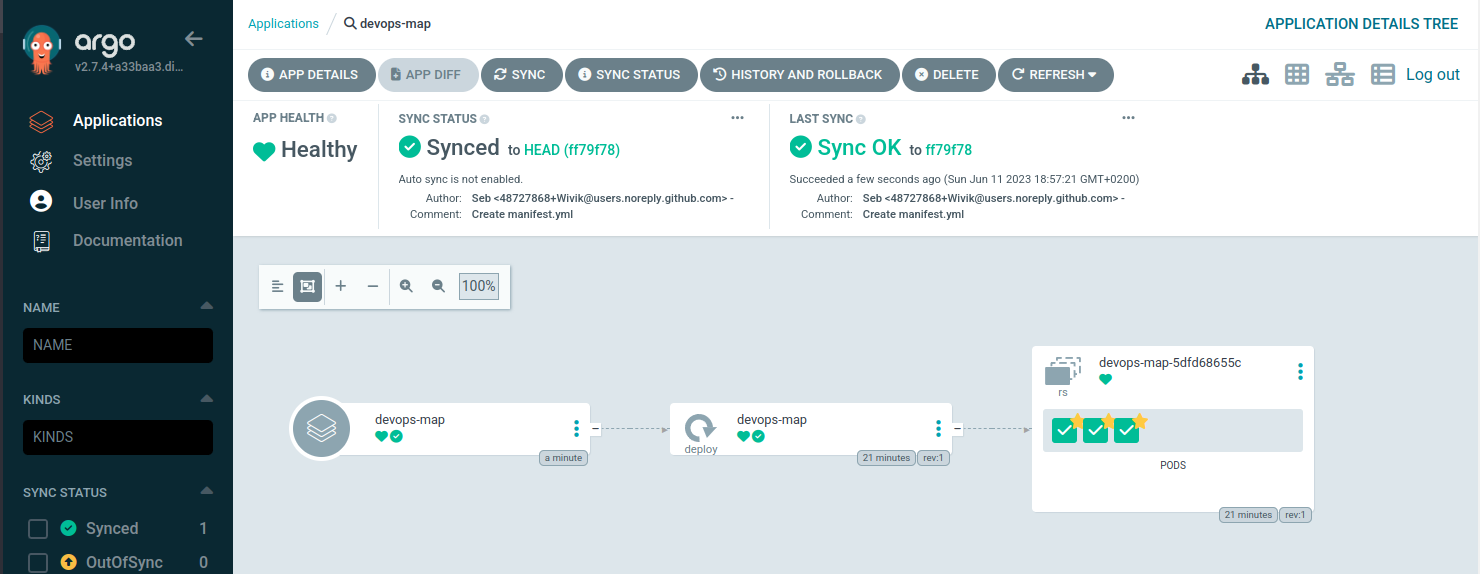
This application is synced and run as expected.
Now, I commit a new version of the image to deploy.
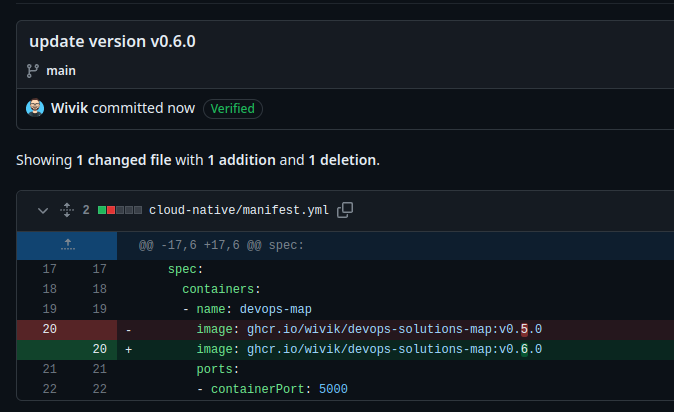
Let’s check my GitOps agent again.
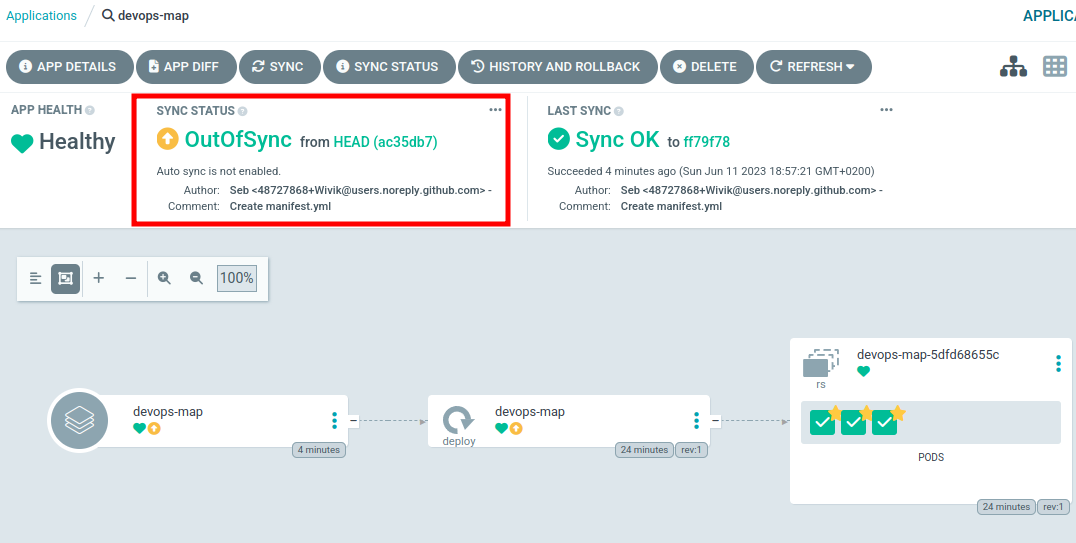
My agent noticed a difference in the repository and warn the application is Out of sync. Now you must ask : why didn’t it applied the change ? GitOps should be automated since the commit is the trigger.
The answer is : I’ve set it in manual mode for the demonstration. Some Agents can be put in manual mode.
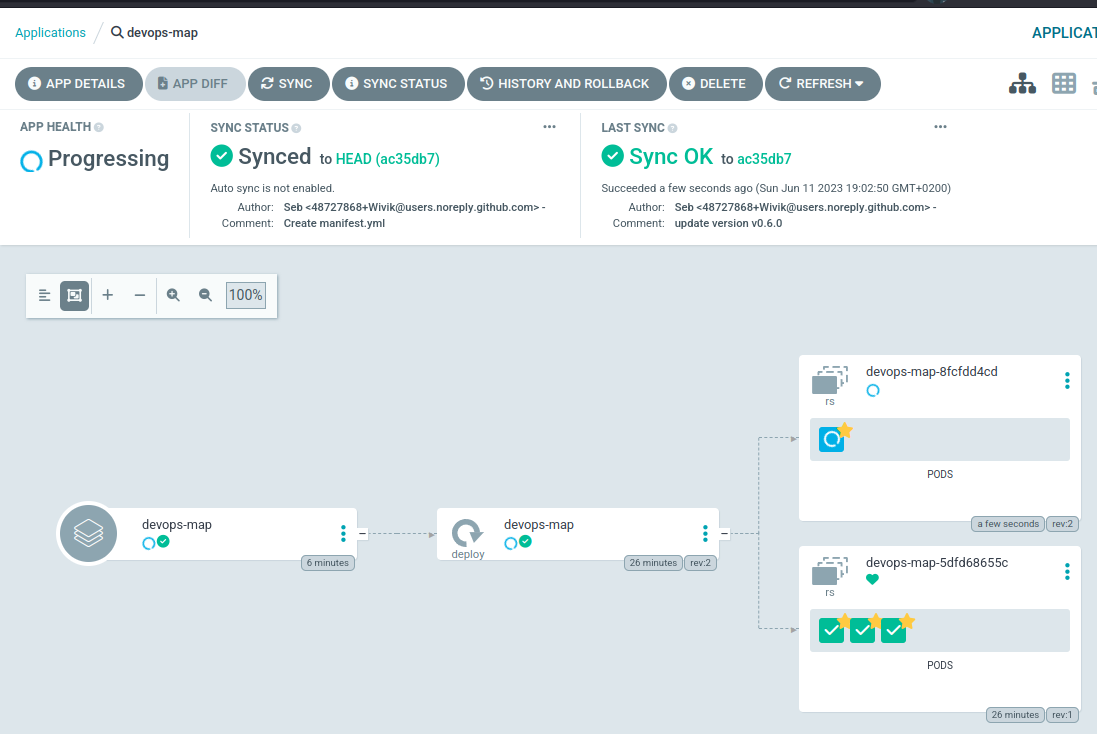
I’ve clicked on “Sync”, the new version is being created and the previous one will be destroyed. After a minute, I see the version being updated to my last commit.
LAST SYNC
Sync OK to ac35db7
Succeeded a minute ago (Sun Jun 11 2023 19:02:50 GMT+0200)
Author: Seb <48727868+Wivik@users.noreply.github.com> -
Comment: update version v0.6.0
It was a mistake, I want to rollback. My Agent knows the history and can do it. I click on rollback, the previous version is deployed an the new one is destroyed.
Please note that the rollback feature may varying according to the used Agent. In my case, I’ve used Argo-CD (check the tools below) which is based on Git history and also has its own database.
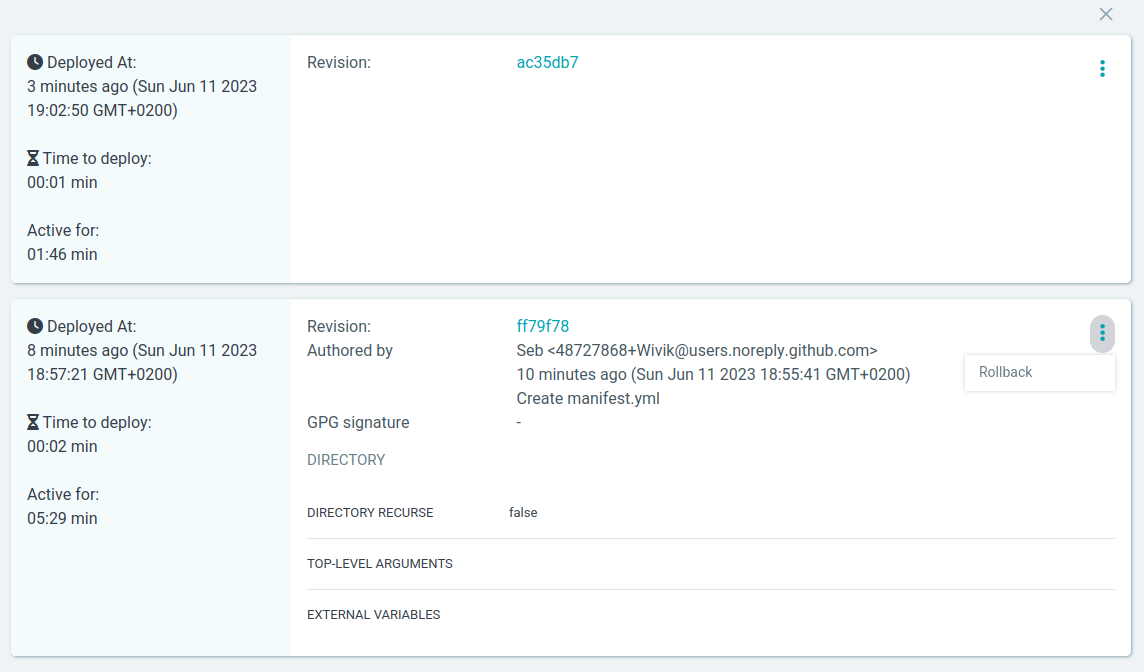
But I’m still out of sync since the main branch in the Git repository considers the v0.6.0 as the one to be deployed.
Let’s activate Auto mode. Once I’ve did this, the application got bumped to v0.6.0 as expected.
Let’s do some naughty things : I’ll apply a manifest file I have locally on the cluster to rollback to v0.5.0. Let’s see what’s happening…

I apply the manifest, the deployment is updated. But…

Immediately after, the GitOps agent said : “NOPE”, that’s not the desired state. The pod is being immediately terminated.
Some GitOps tools
So, now we talked about the process, let’s talk about tools.
Argo-CD
The GitOps agent I used is Argo-CD, which is currently the leader product for this use-case. Argo-CD is a free and open source product licensed under Apache 2.0 that is installed on a Kubernetes cluster. The product has been developed by the company Inuit and is now maintained by the Argo-CD Project, an entity hosted by the Cloud Native Computing Foundation (CNCF). As a Kubernetes native application, Argo-CD can be itself managed with a GitOps pattern. So you can use Argo-CD on a “main” cluster to deploy it on remote instances. In the other available architectures, Argo-CD can be directly used on the local cluster where it is installed (which is, actually, the default use case), or you can create a central instance that deploys on remote clusters.
One of the main interest of Argo-CD is its GUI that displays the objects deployed on the cluster. It’s a good way for non-initiated to understand the relations between the Kubernetes objects.
Argo-CD supports various deployment methods such as Kubernetes manifests, Kustomize, Helm charts, etc.
If you don’t know about these notions, it’s not a problem. To simplify, they’re various way to produce and package Kubernetes manifest files.
Fleet
Fleet is the GitOps solution integrated with Rancher, a Kubernetes clusters management system. The product is also available as a Free and open source software licensed under Apache 2.0. Rancher has been developed by Rancher Labs, a company acquired in 2020 by the German SUSE, an open-source company behind SUSE Linux and also some Kubernetes-specialized distributions. If Fleet was at first an agent to manage Rancher’s components on the clusters it operates, it is now a complete GitOps tool that can also manages the applications deployed on the clusters with groups and roles.
One of the good sides of Fleet is that it’s a part of a Kubernetes management suite, so it was designed in this way unlike Argo-CD which remains a standalone tool (that can also be configured to reproduce Fleet’s behavior). However, unlike Argo-CD, it cannot produce the user-friendly graphical representation of the application’s components at my knowledge. Fleet also have a specific feature using a file named fleet.yaml. If this file is present with the deployment manifests, it will permit to customise them.
Flux
Flux is the product I know the least because I’ve never worked with. Developed by Weaveworks, a company that produces monitoring tools for Kubernetes. It’s now also a part of the CNCF incubating project. Flux is also a free and open source project licensed under Apache 2.0. Flux is a GitOps tools that focuses on the continuous delivery on Kubernetes clusters. Including Git, this tool can also monitor the container registries to detect new image version in order to deploy it.
To summarize
With the demonstration, we saw that GitOps is a method that can provides a reliable deployment strategy that can also be audited and controlled. It will ask some work, especially organizational, to go to this method, but honestly, when you tried it you don’t want to go back.
